
Il est parfois des pratiques d’ingénierie du développement logiciel qui amène tellement, qu’elle mérite vraiment d’aider à leurs diffusions. Et sans que l’on ne comprenne vraiment pourquoi, ces pratiques peinent à trouver leurs places et font face a de nombreuses interprétations. C’est le cas de la pratique du Test Driven Development, le fameux TDD dans le domaine du software craftmanship, dont la traduction est le développement guidé par les tests. Je vais donc ici vous fournir mon interprétation (une de plus) et ma vision de cette pratique que j’affectionne depuis une dizaine d’années.
La confusion de cette discipline
Comme son nom ne l’indique pas très clairement, cette pratique, cette discipline n’est pas une pratique de tests. Bien que possédant le mot test dans son nom, cette pratique vise en premier lieu un tout autre aspect du développement logiciel. Cet aspect est le développement itératif de la fonctionnalité. L’idée principale que je donnerais pour cette pratique est la suivante : « Pour développer une fonctionnalité donnée, nous allons nous concentrer successivement sur des aspects partiels de la fonctionnalité et ainsi augmenter progressivement les capacités de notre logiciel jusqu’à atteindre le développement global de la fonctionnalité« .
L’idée derrière le TDD est la suivante, résoudre un gros problème est souvent difficile, par contre découper ce problème en plus petits problèmes rend la résolution des petits problèmes plus simple, nous gagnons donc en efficacité. Nous retrouvons ici le postulat suivant « plus c’est petit, plus c’est simple« .
Afin d’étayer cette définition encore très abstraite prenons un exemple dans le cadre du développement en TDD outside-in (nous reviendrons plus tard sur les variantes) d’une fonctionnalité de calcul du montant total d’un panier composé de lignes de produits. Les lignes de produits sont elles mêmes composées d’un prix unitaire du produit et de la quantité de ce produit dans le panier.

Découper le problème
Bien que cet exemple soit très simple il va permettre de montrer les principes du TDD. Dans notre exemple, nous allons découper le problème comme cela : le montant total du panier est équivalent à la somme du montant de chaque ligne de produits. Cette première conception semble tout à fait réaliste et semble même assez simple à réaliser, seul problème à ce jour nous n’avons pas le montant de chaque ligne de produits. C’est un des concepts du TDD outside-in on part du besoin depuis l’extérieur du logiciel, on part du comportement que l’on souhaite, ici l’on souhaite pouvoir avoir le montant total du panier et ensuite nous « descendons » dans la hiérarchie des éléments en faisant comme si les moyens à notre disposition étaient déjà présents afin de découper le problème. Ici on part du principe que nous serons capable d’avoir le montant de chaque ligne à l’avenir, on pourra alors facilement réaliser la somme de ces lignes. On répète l’opération de « descente » dans la hiérarchie des éléments jusqu’à répondre entièrement au problème initial.
On voit ici que la conception par découpage du problème, petit pas par petit pas est au coeur du TDD. Mais le TDD amène avec lui d’autres aspects essentiels, la concentration unitaire et le juste nécessaire.
Concentration unitaire
Afin de permettre cette descente dans la hiérarchie de vos éléments, de vos abstractions (ok de vos objets dans de nombreux cas), le Test Driven Development propose de se concentrer sur chacun des aspects partiels de la fonctionnalité de manière unitaire (là vous me voyez venir). La pratique qu’il préconise pour cela est donc la pratique des tests. Encore une fois en partant du postulat plus c’est petit, plus c’est simple, le TDD préconise de ne pas prendre en compte les autres aspects partiels de la fonctionnalité lors de la descente. Pour cela nous allons pratiquer le test automatique en mode « test first » et unitaire. Comment cela se traduit en pratique ?
Les trois étapes du TDD
S’il y a un point qui fait débat sur le TDD, c’est bien celui-ci, certains aiment à dire que le TDD revient à écrire un test avant d’écrire le code source de production, c’est une simplification tout à fait juste mais assez incomplète du processus global initialement proposée par Kent Beck lors de la création de la pratique.
Le Test Driven Development d’un point de vue code se décompose autour de deux éléments, d’une part le code source de production, c’est le code de votre application qui sera exécuté lors de l’accès à votre application notamment en production. D’autre part, le code source de tests, c’est le code qui va lancé le code source de production et vérifier son comportement.
La pratique du TDD se décompose en trois étapes avec pour chacune une couleur associée :
- Écrire du code de tests qui échoue (red)
- Écrire du code de production qui fait passer les tests (green)
- Remanier les deux parties de code source (production et tests) (blue)
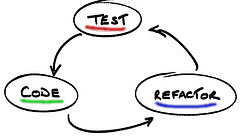
Pour détailler ces trois étapes, cela implique qu’avant chaque modification du code de production, je dois écrire un premier test qui démontre que le code source de production actuel ne répond pas à notre aspect partiel, notre cas d’utilisation de la fonctionnalité. Je dois alors avoir un unique test qui échoue afin de me concentrer uniquement sur cet aspect partiel de la fonctionnalité globale. Ensuite seulement je peux réaliser du code de production pour faire passer ce test. Et enfin je remanie mon code source de production et de tests, je ne vais pas détailler ici la pratique de la troisième étape, le refactoring, cette troisième étape bien qu’essentielle pour un code long terme est bien souvent oubliée ou ignorée par manque de temps. C’est une pratique à part entière qui mériterait bien son article dédié.
Avec cette succession d’étapes qui se répètent aspect partiel après aspect partiel, les tests permettent de se concentrer uniquement sur un aspect après l’autre, les tests ne sont finalement qu’un moyen d’arriver à la concentration unitaire. L’avantage des tests qui sont dans le cadre du TDD automatisé et non manuel (on a écrit du code dans ce but), est que nous allons pouvoir exécuter ces tests tout au long de la vie du logiciel, ce qui en fait un effet de bord incroyablement précieux et c’est une des raisons qui fait que certaines personnes pensent le TDD comme étant en premier lieu une méthode de tests plus qu’une méthode de développement.
Juste nécessaire
Un autre avantage que procure les tests et notamment de les écrire avant le code de production et dans l’écriture de la juste nécessaire quantité de code source de production.
En effet, lorsque l’on écrit un test afin de démontrer que ce cas-ci n’est pas résolu, on s’assure ainsi qu’il y a bien nécessité d’écrire du code source. Si nous reprenons notre exemple sur le test qui confirmerait la capacité du panier, s’il est vide, à retourner un montant total à 0, celui-ci pourrait très bien être déjà résolu dans le cas où nous aurions déjà traité le cas standard à savoir un panier non vide.
Pourquoi ? Parce que la somme d’une liste de lignes de produits vide retourne en fonction de l’implémentation peut être déjà 0. Sans tests nous aurions étaient tentés par le fait d’injecter une vérification sur le fait que le panier soit vide avec une structure « if » et donc nous aurions écrit du code source supplémentaire et inutile.
Ce point simplifie par la suite la maintenance et la conception de notre application, ce qui la rend plus robuste sur le long terme et répond une nouvelle fois au postulat « plus c’est petit, plus c’est simple« .
Un autre cas où le TDD amène la juste quantité de code source de production est le lancement très régulier des tests. Lorsque nous sommes dans l’étape où un unique test échoue (red), le premier objectif est de faire passer les tests (green). Pour cela, nous allons aller au plus simple, même si nous devons coder un retour en dur, ici une nouvelle fois, nous souhaitons se concentrer sur un unique aspect de notre fonctionnalité qui est répondre a un premier cas d’usage en « faisant passer les tests au vert« .
À ce moment précis nous savons que nous ne traitons qu’un cas parmi d’autres vient alors le temps de généraliser un peu plus en écrivant un second cas de test différent du premier qui va donc prouver que nous avons besoin de généraliser le code source de l’application. Lors de la réalisation du code source de production, c’est pareil si les tests passent alors je dois arrêter l’écriture du code source de production et écrire un nouveau cas de test qui prouve que je dois reprendre l’écriture de ce code source de production.
Ces étapes sont sur des temporalités tellement courtes que ce n’est pas du gâchis, nous généralisons donc seulement quand cela est nécessaire guidé par les tests que nous avons écris.
L’on voit ici de l’importance de se laisser guider par les tests et le comportement souhaité. Si nous sentons que nous avons encore besoin de généraliser un peu plus notre code source de production, alors il nous faut le démontrer par un cas de test supplémentaire.
Les trois lois du TDD
Les trois lois du Test Driven Development ont émergés afin d’entériner le principe d’un seul test en échec et d’un minimum de code source de production pour le faire passer. Ces trois lois sont les suivantes (source wikipédia Test Driven Development) :
- « Vous ne pouvez pas écrire de code de production tant que vous n’avez pas écrit un test unitaire qui échoue. »
- « Vous ne pouvez pas écrire plus d’un test unitaire que nécessaire pour échouer, et ne pas compiler revient à échouer. »
- « Vous ne pouvez pas écrire plus de code de production que nécessaire pour que le test unitaire actuellement en échec réussisse. »
Ces trois lois font souvent débat dans les différentes approches, car elle nécessite une grande rigueur, voir parfois pour certaines approches, faire des étapes intermédiaires qui peuvent sembler inutile ou robotique. Par exemple, si je souhaite vérifier que pour mon panier contenant une ligne de produit dont le prix unitaire est 10 euros et la quantité 1 alors le montant total de mon panier doit être de 10 euros, le premier code source de production écrit dans la méthode montant_total sera un simple retour de la valeur 10 euros.
Dans ce contexte, le développeur sait très bien que ce n’est pas le code source de production final, il n’y a pas de doutes que ce code n’est pas assez généralisé. Mais l’application des trois lois permet aux développeurs d’écrire un second test qui permettra de justifier la généralisation et par conséquent qui rendra le code source de production plus robuste car cette généralisation sera testée.
Si nous reprenons notre exemple, le second test sera sur un panier composé d’une ligne de produit avec un prix unitaire de 5 euros et une quantité de 1, alors le seul moyen de faire passer les 2 tests sera de généraliser le code source de production.
Un point à garder en tête lors de l’application forte de ces 3 lois est : le code de vos tests se spécialisent de plus en plus pour gérer des cas des plus probables au moins probables alors que le code de production se généralise à chaque tests successif. Cela implique donc de ne pas traiter chacun des nouveau cas avec des structures de type « if » par exemple.
Ce dernier point est intéressant car il n’est pas possible de tester tous les cas (même en utilisant des générateurs de valeurs aléatoires). Dans notre exemple, un produit peut prendre une infinité de valeur par conséquent nous ne serons jamais en mesure d’écrire tout les cas de tests nécessaires, il faut donc généraliser le code de production.
La pyramide de tests
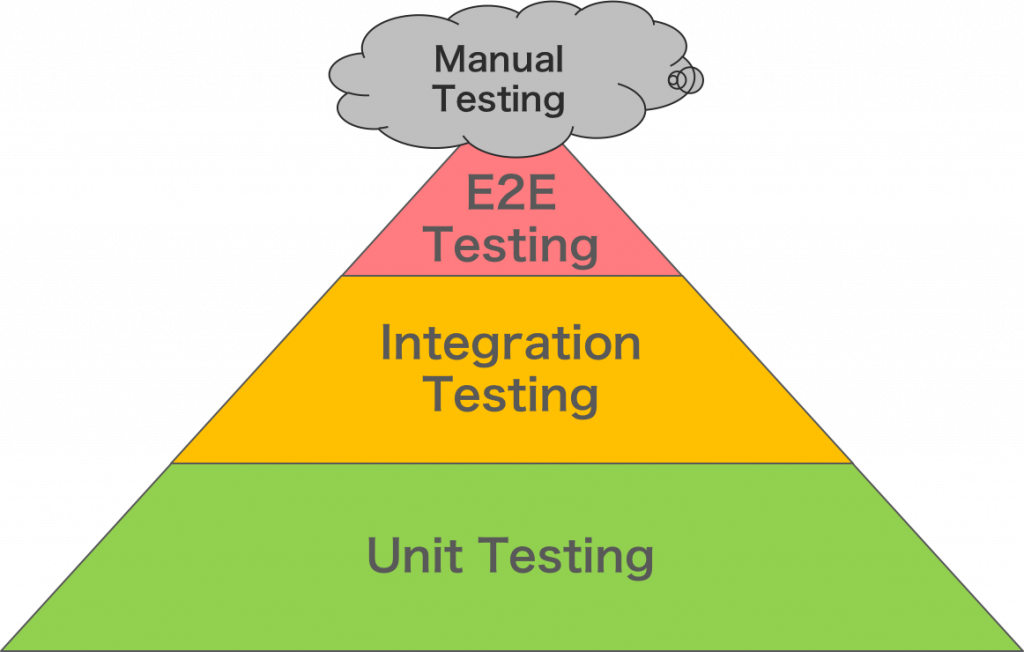
La pyramide de tests est un artefact bien connu dans la gestion de votre stratégie de tests, elle préconise de nombreux tests unitaires (car rapide et à faible coût) puis un niveau intermédiaire de tests d’intégrations (moyennement rapide et moyennement coûteux) puis un niveau faible de tests de bout en bout (peu rapide et assez coûteux) et enfin quelques tests manuels.
Cette pyramide fût longtemps la bible en terme de stratégie de tests. Commençons par une petite description très succincte des types de tests évoqués ci-dessus.
Les tests manuels sont des tests très haut niveaux, on utilise un système similaire à la production en maximisant cette ressemblance afin de voir comment le système réagit suite à l’ajout d’une fonctionnalité. L’environnement utilisé pour cela peut avoir différents noms préproduction, qualification… L’objectif ici est de valider que la nouvelle fonctionnalité peut être déployée et qu’elle s’intègre bien dans le logiciel.
Les tests de bout en bout eux sont des tests similaires aux tests manuels à la différence prêt qu’ils s’exécutent dans un environnement dédié et qu’ils sont automatisés et par conséquent beaucoup moins soumis à l’interprétation humaine sur des aspects visuels ou d’ergonomie. Ici les tests vont couvrir l’ensemble du spectre de l’application de l’interface graphique en passant par le serveur web puis le code source de l’application et enfin une base de donnée par exemple.
Les tests d’intégrations sont des tests visant à prouver que deux éléments d’un système communique bien ensemble, par exemple le code source de production fonctionne bien avec la base de données ou encore avec le serveur web.
Pour les tests unitaires, la notion fut soumise à interprétation, notamment sur le sens du mot unitaire. Certaines approches ont pu désigner par le terme unitaire toute unité de code, soit chaque fonction doit avoir son ou ses tests associés, ou encore chaque classe doit avoir son fichier de test associé et ce sans liaison avec un autre élément du système, on teste donc à un niveau très bas le logiciel.
Depuis un autre mouvement est apparu en plaçant au sein du mot unitaire, l’idée de concept ou de besoin, de fonctionnalité il en résulte alors que par exemple toute portion de code accessible depuis l’extérieur du système doit être testée et que cette notion d’unitaire peut finalement être plus ou moins fine en fonction du contexte. Ce second mouvement amène alors la notion de tests d’acceptation entre les tests unitaires fins et les tests d’intégrations. Ces tests d’acceptation n’étant finalement que des tests unitaires plus gros que les tests unitaires fins.
Prenons un exemple, si je teste ma fonctionnalité montant total et que pour réaliser cette fonctionnalité, j’ai dans un premier temps (avant refactoring) codé au sein d’une unique méthode. Si je découpe cette méthode pour la composer de 3 méthodes distinctes, en fonction de la lecture initiale de la pyramide je devrais associé à chaque méthode un test pour respecter le fait d’avoir une base de tests unitaires couvrant le maximum de code source de production. Ou alors selon le second mouvement, je pourrais ne tester que la méthode globale de la fonctionnalité et rendre les 3 autres méthodes privées, en considérant l’unité au niveau de la fonctionnalité, au niveau de la méthode publique.
Avec cette seconde approche, nous avons toujours la même couverture de test car les 3 méthodes privées sont indirectement testées par le test de la méthode publique, l’avantage ici est que les tests se superposent beaucoup moins et sont donc plus robuste. Le changement sera donc plus facilement intégrable à l’avenir et évitera pour une modification d’avoir de nombreux tests à revoir.
Double boucle du TDD
Comme nous l’avons vu, avec une approche par l’extérieur (outside in), on découpe le problème en considérant que l’on sera capable d’augmenter la capacité du logiciel sur les éléments plus bas dans la hiérarchie car plus simple (ils ont moins de responsabilités). La double boucle du TDD se décompose comme ceci lors d’une approche outside in.
Premièrement je vais tester mon logiciel par le moyen d’accès à ma fonctionnalité, une api REST par exemple. Mon premier test sera donc de tester la capacité de mon logiciel à me fournir un point d’accès avec le comportement global souhaité par exemple le calcul du montant total de mon panier. Ce test est à un niveau test d’intégration car je vérifie que mon contrôleur par exemple m’apporte le comportement attendu en passant par le code métier et en se connectant à la base de données. Notons ici que je suis sur une approche assez classique CRUD utilisé au sein d’un framework MVC par exemple, nous n’allons pas ici pour le moment entrer dans la notion d’architecture hexagonale ou d’autres types d’architecture permettant le découplage entre code métier et code d’infrastructure, l’architecture hexagonale mériterait aussi son propre article.
J’ai donc un premier test très haut niveau, c’est ma première boucle, ensuite je vais descendre à un niveau plus bas lorsque je vas vouloir amener du comportement sur ce point d’accès, je vais donc pour cela écrire un nouveau test qui sera un test unitaire pour le comportement partiel de ma fonctionnalité et c’est ainsi que j’entre dans ma seconde boucle du TDD car le premier test ne passant pas je le commente le temps de faire passer le test de la seconde boucle. Une fois cela fait je dé-commente mon premier test et je passe à l’aspect partiel suivant et ainsi de suite.
Le principe peut se répéter plusieurs fois en fonction de votre fonctionnalité et de la façon de découper votre problème. L’idée principale étant de partir de l’extérieur, de coder comme ci vous aviez les aspects partiels nécessaires déjà réalisés. Puis de réaliser unitairement chacun de ces éléments partiels. Enfin vérifier que votre test de haut niveaux passe bien.
Les variantes
Il existe de nombreuses variantes dans la pratique du TDD, différents principes ont émergés au cours des années. L’un des premier principes étaient le Test First Design, dont la principale pratique était d’écrire les tests avant le code source de production. Puis est arrivé le fait qu’il n’y ai qu’un seul test qui échoue et ainsi de suite.
Pour citer quelques variantes des plus connues on retrouve le TDD inside out, le TDD outside in qui sont les deux principales approches connues.
La première va partir de l’intérieur du système vers l’extérieur. On commence donc par les éléments les plus bas dans notre hiérarchie d’abstractions et cette approche va demander des tests individuels de chaque méthode créée pour respecter les principes du TDD, il y aura donc, lorsque l’on remontera vers les éléments plus haut dans la hiérarchie, des superpositions de tests. Cette redondance peut être lourde à gérer au fil du temps et amener une certaine fragilité.
La seconde approche va partir de l’extérieur du système vers l’intérieur. On commence ici par le comportement souhaité, les cas d’utilisation des éléments publiques de notre système, par exemple une api. On va ensuite écrire le code juste nécessaire pour répondre au comportement souhaité et en ajoutant comportement après comportement nous allons étendre les capacités de notre application en descendant dans les éléments de notre hiérarchie. Tout remaniement de code ayant pour but de changer la forme sans modifier le comportement, nous n’aurons alors pas besoin d’écrire de tests supplémentaires et la superposition de tests se trouvera bien moindre que dans la première approche.
Une nouvelle approche est en train de se répandre, basé sur l’outside in TDD elle se nomme outside in diamond, …
Outside In Diamond
L’approche outside in diamond utilise de nombreuses notions de l’industrie, elle se pratique notamment avec une gestion forte de la différenciation du code métier et du code d’infrastructure, des notions que vous retrouverez par exemple dans l’architecture hexagonale.
Dans cette approche, il va être conseiller d’écrire le maximum de tests d’acceptations (tests unitaires assez gros à un niveau fonctionnalité par exemple), plus que de tests unitaires fins d’où la forme en diamant.
Ici la double boucle du TDD appliqué à un système découplé entre le code métier et le code d’infrastructure va permettre d’avoir des tests rapides au niveau tests unitaires fins ET tests d’acceptations, car nous n’allons pas démarrer de base de données ou de serveur web pour ceux-ci, mais l’architecture va permettre de simuler l’appel comme s’il provenait d’un serveur web.
Par contre cette double boucle commencera alors par un test d’acceptation plutôt qu’un test d’intégration, mais n’entraînera pas forcément la superposition avec des tests unitaires fins si cela n’est pas nécessaire nous aurons donc bien plus de tests d’acception que de tests unitaires ou de tests d’intégrations. Cette double boucle ne sera donc pas réalisée systématiquement mais seulement dans les cas complexe à faire émerger.
J’affectionne particulièrement cette approche, car je l’utilisais déjà sur des systèmes de framework CRUD – MVC avec les tests d’intégrations à la place des tests d’acceptation, ici avec l’approche architecture découplée on accélère les tests ce qui est un point positifs indéniables.
Les avantages de cette approche sont pour moi important, on ne code que du code nécessaire et on ne perd pas en couverture de tests, on est plus rapide sur l’exécution des tests et on est donc plus efficace.
Pour aller plus loin, cette pratique est notamment diffusé par Thomas Pierrain :
- https://tpierrain.blogspot.com/2021/03/outside-in-diamond-tdd-1-style-made.html
- https://www.youtube.com/watch?v=djdMp9i04Sc
Pour finir
En quoi le fait d’écrire le test avant le code source de production est-il important ?
Premièrement lorsque l’on écrit les tests avant on ne les oublie pas, la pire situation que vous pouvez rencontrer en fin de session de développement est un test qui ne passe pas sans code source en face, dans l’approche classique de l’écriture des tests à posteriori, il n’est pas rare qu’une urgence vous sorte de votre session de développement et que vous vous retrouviez avec du code source de production sans tests en face, ce qui est bien plus dangereux à long terme. De même en écrivant en premier lieu le test votre code source de production sera testable ce qui n’est pas toujours simple dans l’approche à posteriori.
Second point, le fait d’écrire un test en premier en partant du comportement souhaité va vous orientez dans le nommage des éléments nécessaires, ce nommage traduira plus simplement votre intention de plus, l’architecture de votre solution sera aussi émergente et en juste à temps. Le changement ne deviendra plus un problème et vous aurez moins besoins de faire de l’architecture lourde en amont mais une architecture plus légère au fur et à mesure de la découverte des besoins.
Petit bonus, vos tests sont importants autant que le code source de production, ils vous seront alors utiles sur bien des aspects. Les tests sont votre documentation d’utilisation de votre application. Chacun des tests représentant un cas d’usages possibles de votre application, pensez donc à en prendre soin afin de maximiser leurs utilisabilités.
Comme nous avons pu le voir je suis convaincu par cette pratique depuis de nombreuses années, je vous ai résumé quelques aspects qui m’ont convaincus au cours de ces années, bien évidemment il y a de nombreuses autres approches, chacune avec leurs avantages et leurs inconvénients, pas de silver bullet une nouvelle fois.
Cette pratique nécessite une certaine rigueur et une changement de paradigme notamment sur l’écriture du test en premier qui peut se révéler douloureux dans les premiers mois mais une fois que l’on a en main cette pratique on a du mal à la lâcher.
A bientôt pour d’autres pratiques craft.
Image par PublicDomainPictures de Pixabay